Costruisci la scena una volta.
Inquadrala all'infinito.
Esempio reale: la Piazza del Casinò di Monte Carlo, modellata una sola volta in Blender. Da lì, ogni mappa che serve a ControlNet.
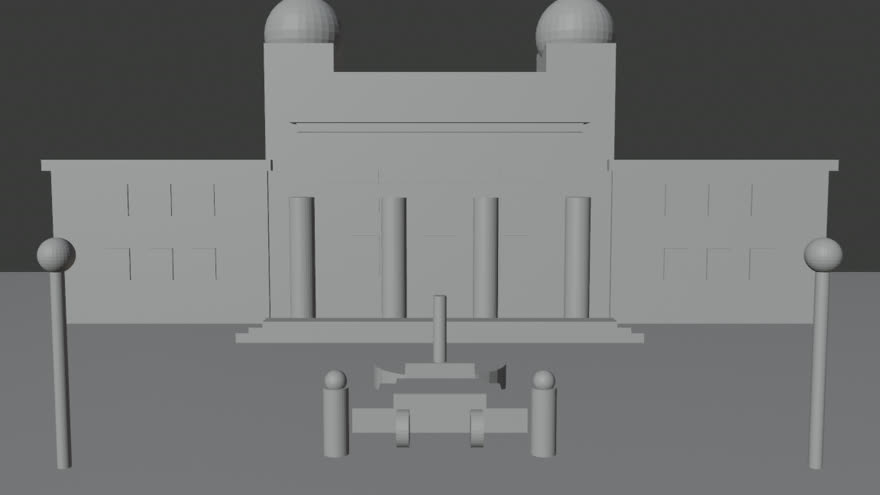 01 Greybox
01 Greybox
 02 Depth
02 Depth
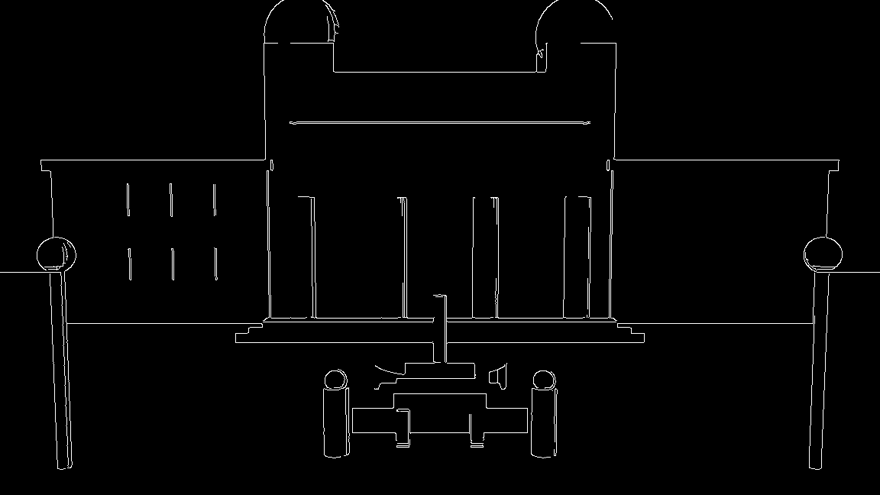 03 Canny
03 Canny
 04 Render AI
04 Render AI
01–03: mappe reali generate da montecarlo_greybox.py in Blender headless · Pannello 1 "wide establishing" · nessun ritocco. 04: render AI finale — motore brain-claude / FreeFuse, coppia coesa in una sola generazione.
Le pose non si indovinano.
Si costruiscono in 3D.
I vecchi estrattori di pose 2D (OpenPose) non sanno se un braccio è davanti o dietro il petto. Ambiguità che l'AI risolve a caso — spesso male.
Pipeline pose · stato attuale
 Pannello 6 · reso
Pannello 6 · reso
Il greybox scena copre già camera 3 · manca solo il rig posato
Lo stesso volto,
in venti tavole diverse.
Due strade, stesso obiettivo: che il personaggio resti riconoscibile senza fluttuazioni di viso o abiti tavola dopo tavola.
Si allena un piccolo modello (15-30 immagini) sul personaggio. Attivabile con una parola chiave. Massima fedeltà, richiede training una tantum.
Basta un'unica immagine di riferimento del volto. Nessun training: ideale per personaggi secondari creati al volo.
Caso reale · "Bond girl"
 Coppia · reso
Coppia · reso
Guido-007 usa già un LoRA collaudato. La Bond girl è un personaggio fittizio: basta una ref del volto, poi PuLID la ripete ovunque.
La ricetta: una piazza,
tre inquadrature.
Lo stesso greybox della Piazza del Casinò, tre camere diverse. Nessuna nuova modellazione: solo nuove mappe.
Camera 1
Campo lunghissimo. La facciata Belle Époque, l'Aston Martin ferma davanti all'ingresso.
 Camera 2 · ~120°
Camera 2 · ~120°
Piano americano ruotato. Stessa piazza, stessa auto: la novel-view che il prompt puro non garantirebbe mai.
 Camera 3 · rialzata
Camera 3 · rialzata
Ripresa dall'alto. Dolly sulla scalinata d'ingresso — stessa geometria, terza angolazione.
La stessa scena. Foto o disegno.
Stesso personaggio, stessa composizione, stesso "servizio fotografico". Cambia solo lo stile: il motore passa dal fotorealismo alla tavola disegnata senza rifare nulla. Per uno studio di fumetto, il valore è qui.
Foto FotoFoto
FotoFoto Disegno
Disegno Disegno
Disegno Disegno
DisegnoStesso motore (brain-claude / FreeFuse), stesso seed. In alto il render fotografico, sotto lo stesso pannello in stile graphic novel — cambiato solo il prompt di stile. Nessun ridisegno.